三、PySpark环境安装
PySpark: 是Python的库, 由Spark官方提供. 专供Python语言使用. 类似Pandas一样,是一个库
Spark: 是一个独立的框架, 包含PySpark的全部功能, 除此之外, Spark框架还包含了对R语言\ Java语言\ Scala语言的支持. 功能更全. 可以认为是通用Spark。
| 功能 | PySpark | Spark |
| 底层语言 | Scala(JVM) | Scala(JVM) |
| 上层语言支持 | Python | Python\Java\Scala\R |
| 集群化\分布式运行 | 支持 | 支持 |
| 定位 | Python库 (客户端) | 标准框架 (客户端和服务端) |
| 是否可以Daemon运行 | No | Yes |
| 使用场景 | 生产环境集群化运行 | 生产环境集群化运行 |
若安装PySpark需要首先具备Python环境,这里使用Anaconda环境,安装过程如下:
使用spark-shell方式可以进入spark的客户端,但是这个客户端编码是需要scala代码的,我们并不会。我们希望可以使用python代码操作spark。所以可以使用pyspark的客户端,但是一执行pyspark,就报出如下的错误:

原因: PySpark运行需要使用Python3.x的环境 解决办法: Anaconda安装Python3的环境。
通过Anaconda安装Python3
Anaconda(水蟒): 是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 conda、Python 等 180 多个科学计算包及其依赖项,并且支持所有操作系统平台。
anaconda是一个大集成者, 包含有python的环境. 同时还包含各种用于数据分析python库, 一旦使用anaconda可以在一定程度上避免安装各种Python的库
anaconda提供一种虚拟化的测试, 可以基于anaconda虚拟出多个python的环境, 而且各个环境都是相对独立的 我们称为沙箱环境
为什么需要使用虚拟环境: 是因为python各个版本都是互相不兼容, 比如说python2 和python3 不兼容 甚至大家都是python3, 但是python3.8 无法兼容python3.7
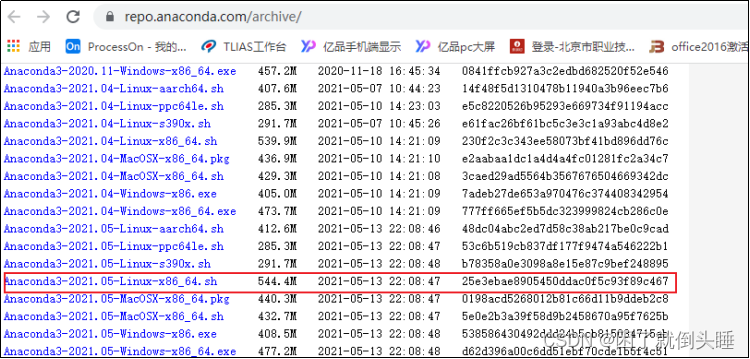
1.下载Anaconda环境包
安装版本:https://repo.anaconda.com/archive/
Python3.8.8版本:Anaconda3-2021.05-Linux-x86_64.sh
2.安装Anaconda环境(三台节点都是需要安装)
此环境三台节点都是需要安装的, 以下演示在node1安装, 其余两台也是需要安装的
上传软件到/export/software目录下
| cd /export/software rz 上传Anaconda脚本环境 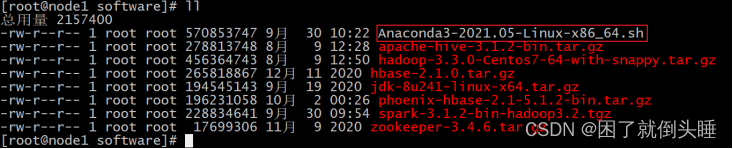 执行脚本: sh Anaconda3-2021.05-Linux-x86_64.sh 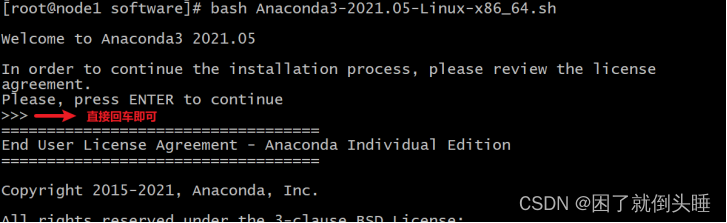 不断输入空格, 直至出现以下解压, 然后输入yes  此时, anaconda需要下载相关的依赖包, 时间比较长, 耐心等待即可...., 在等待中如果需要输入yes/no, 直接输入yes   配置anaconda的环境变量,三个节点都需要进行相同的操作: vim /etc/profile ##增加如下配置 #ANACONDA_HOME export ANACONDA_HOME=/root/anaconda3/bin export PATH=$PATH:$ANACONDA_HOME 修改bashrc文件,三个节点都需要进行相同的操作: vim ~/.bashrc 在文件最上面添加如下内容: export PATH=~/anaconda3/bin:$PATH 重新加载环境变量: source /etc/profile  |
说明:
| profile 其实看名字就能了解大概了, profile 是某个用户唯一的用来设置环境变量的地方, 因为用户可以有多个 shell 比如 bash, sh, zsh 之类的, 但像环境变量这种其实只需要在统一的一个地方初始化就可以了, 而这就是 profile. bashrc bashrc 也是看名字就知道, 是专门用来给 bash 做初始化的比如用来初始化 bash 的设置, bash 的代码补全, bash 的别名, bash 的颜色. 以此类推也就还会有 shrc, zshrc 这样的文件存在了, 只是 bash 太常用了而已. 拷贝到其他节点:scp Anaconda3-2021.05-Linux-x86_64.sh node2:$PWD |
3.启动anaconda并测试
注意: 请将当前连接node1的节点窗口关闭,然后重新打开,否则无法识别
| 输入 Python启动:  |
如果大家发现命令行最前面出现了 (base) 信息, 可以通过以下方式, 退出Base环境
| vim ~/.bashrc 拉到文件的最后面: 输入 i 进入插入模式 将以下内容添加到最后面: conda deactivate
|

4.Anaconda相关组件介绍
Anaconda(水蟒):是一个科学计算软件发行版,集成了大量常用扩展包的环境,包含了 conda、Python 等 180 多个科学计算包及其依赖项,并且支持所有操作系统平台。下载地址:https://www.continuum.io/downloads
- 安装包:pip install xxx,conda install xxx
- 卸载包:pip uninstall xxx,conda uninstall xxx
- 升级包:pip install upgrade xxx,conda update xxx
Jupyter Notebook:启动命令
| jupyter notebook |
功能如下:
- Anaconda自带,无需单独安装
- 实时查看运行过程
- 基本的web编辑器(本地)
- ipynb 文件分享
- 可交互式
- 记录历史运行结果
修改jupyter显示的文件路径:
通过jupyter notebook --generate-config命令创建配置文件,之后在进入用户文件夹下面查看.jupyter隐藏文件夹,修改其中文件jupyter_notebook_config.py的202行为计算机本地存在的路径。
IPython:
命令:ipython,其功能如下
1.Anaconda自带,无需单独安装
2.Python的交互式命令行 Shell
3.可交互式
4.记录历史运行结果
5.及时验证想法
Spyder:
命令:spyder,其功能如下
1.Anaconda自带,无需单独安装
2.完全免费,适合熟悉Matlab的用户
3.功能强大,使用简单的图形界面开发环境
下面就Anaconda中的conda命令做详细介绍和配置。
(1)conda命令及pip命令
conda管理数据科学环境,conda和pip类似均为安装、卸载或管理Python第三方包。
| conda install 包名 pip install 包名 conda uninstall 包名 pip uninstall 包名 conda install -U 包名 pip install -U 包名 |
(2) Anaconda设置为国内下载镜像
| conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ conda config --set show_channel_urls yes |
(3)conda创建虚拟环境
| #查看有哪些虚拟环境(沙箱环境) conda env list #创建python3.8.8环境 conda create -n py_env python=3.8.8 #激活环境 conda activate py_env
#退出环境 conda deactivate |
5.PySpark安装(只需要在node1安装即可)
三个节点也是都需要安装pySpark的,本质上只需要在node1安装即可,后续主要基于node1来进行本地测试
6.1(推荐使用的方式)直接安装PySpark(下载好的包)
安装如下:
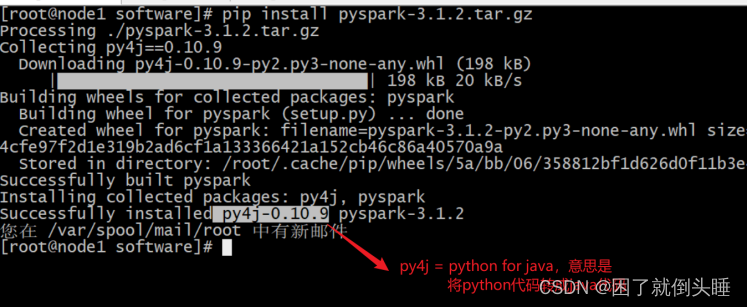
| 使用PyPI安装PySpark如下:也可以指定版本安装 pip install pyspark==3.1.2 或者指定清华镜像(对于网络较差的情况): pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.1.2 # 指定清华镜像源 教室网络非常差怎么办?提前下载到本地,然后直接本地安装: 先将pyspark的jar包上传到node1 /export/software cd /export/software pip install pyspark-3.1.2.tar.gz 如果要为特定组件安装额外的依赖项,可以按如下方式安装(此步骤暂不执行,后面Sparksql部分会执行): pip install pyspark[sql] |
截图如下:
6.2[通用安装]方式2:创建Conda环境安装PySpark
| #从终端创建新的虚拟环境,如下所示 conda create -n pyspark_env python=3.8  #创建虚拟环境后,它应该在 Conda 环境列表下可见,可以使用以下命令查看 conda env list  #现在使用以下命令激活新创建的环境: source activate pyspark_env 或者 conda activate pyspark_env  如果报错: CommandNotFoundError: Your shell has not been properly configured to use 'conda deactivate'.切换使用 source activate #您可以在新创建的环境中通过使用PyPI安装PySpark来安装pyspark,例如如下。它将pyspark_env在上面创建的新虚拟环境下安装 PySpark。 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple pyspark==3.1.2 #或者,可以从 Conda 本身安装 PySpark: conda install pyspark==3.1.2  |
6.3[不推荐]方式3:手动下载安装
将spark对应版本下的python目录下的pyspark复制到anaconda的
Library/Python3/site-packages/目录下即可。
请注意,PySpark 需要JAVA_HOME正确设置的Java 8 或更高版本。如果使用 JDK 11,请设置-Dio.netty.tryReflectionSetAccessible=true,Arrow相关功能才可以使用。
扩展:
| conda虚拟环境 命令 查看所有环境 conda info --envs 新建虚拟环境 conda create -n myenv python=3.6 删除虚拟环境 conda remove -n myenv --all 激活虚拟环境 conda activate myenv source activate base 退出虚拟环境 conda deactivate myenv |
7.初体验-PySpark shell方式
前面的Spark Shell实际上使用的是Scala交互式Shell,实际上 Spark 也提供了一个用 Python 交互式Shell,即Pyspark。
| bin/pyspark --master local[*] |
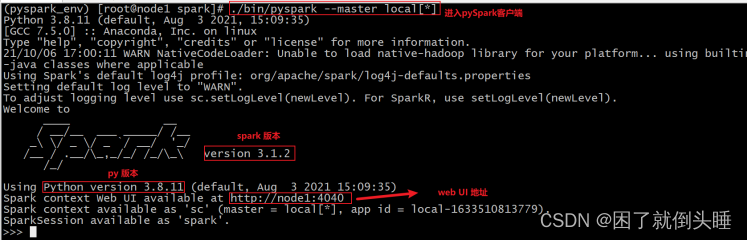
PySpark环境验证计算圆周率
演示: 将spark提供的官方测试python脚本提交到spark的local上,检测spark是否可以正常的运行
[root@node1 bin]#cd /export/server/spark/bin [root@node1 bin]#./spark-submit /export/server/spark/examples/src/main/python/pi.py 100
验证成功截图: